#!/usr/bin/env python3
import paho.mqtt.client as mqtt
import requests
import time
import minimalmodbus
import influxdb
modbusrelay_heizung = minimalmodbus.Instrument('/dev/serial/by-id/usb-1a86_USB_Serial-if00-port0', 2, debug = True)
modbusrelay_heizung.serial.timeout = 0.1
print(modbusrelay_heizung)
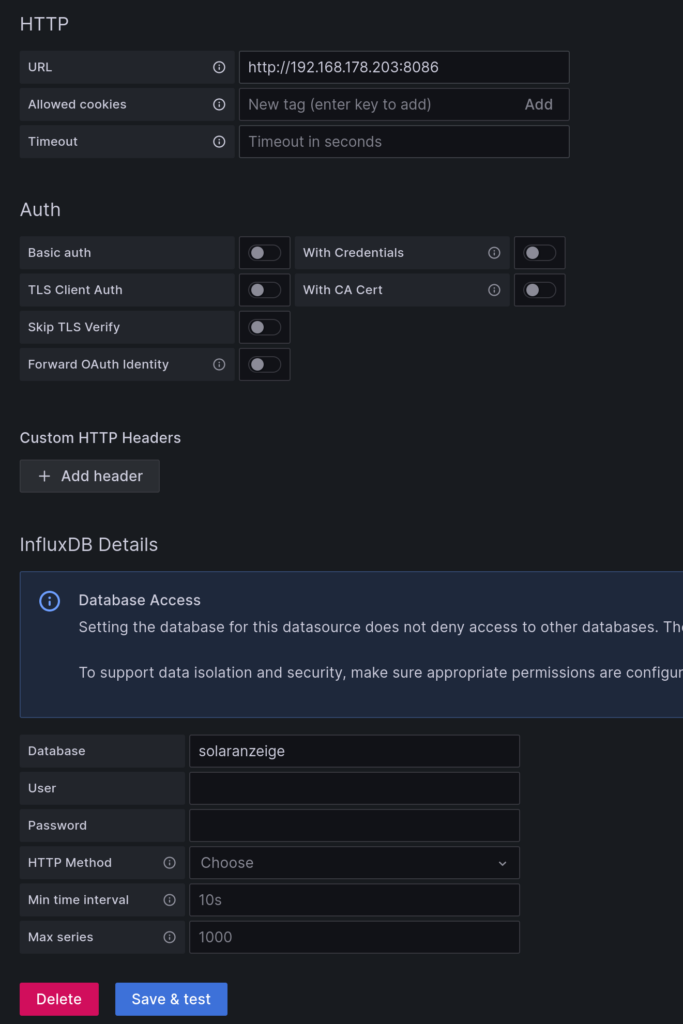
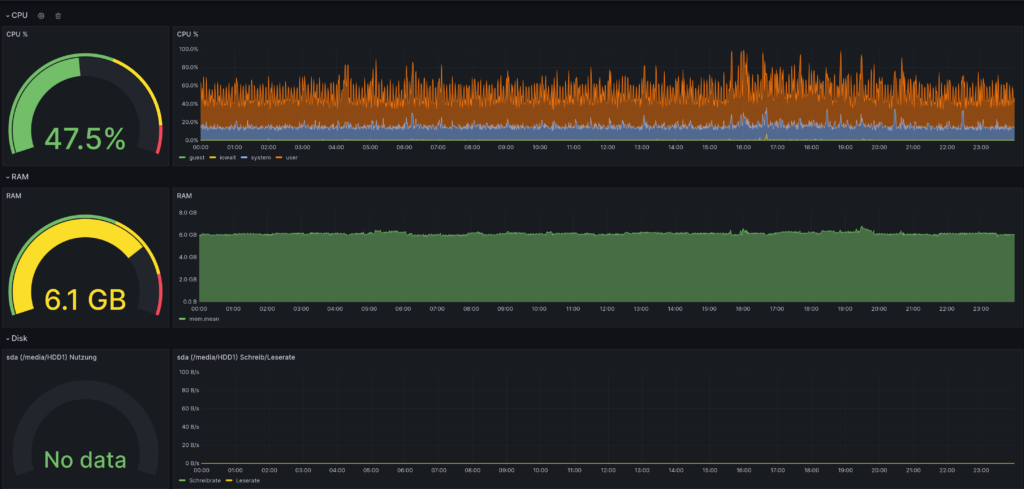
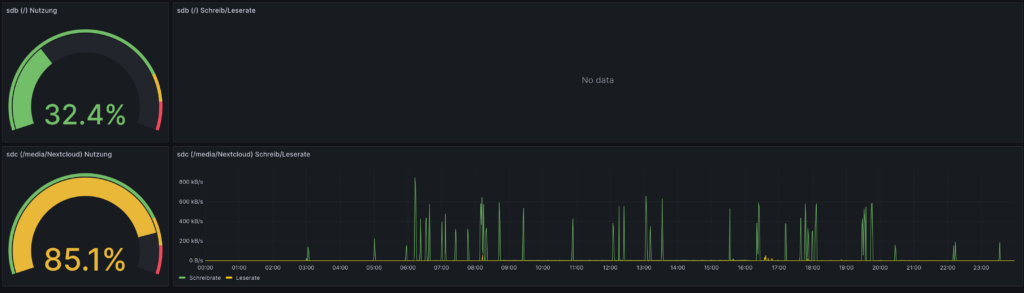
influxclient = influxdb.InfluxDBClient(host="serverpi", port=8086, database="energy")
relais_freigabe = True
def set_relais(relay, state):
if state == "on":
modbusrelay_heizung.write_bit(int(relay)-1, 1)
if state == "off":
modbusrelay_heizung.write_bit(int(relay)-1, 0)
def get_relais():
binary_relais = modbusrelay_heizung.read_bits(0, 8, 1)
print("Relais:" + str(binary_relais))
for i in range(8):
if binary_relais[i] == 1:
client.publish("modbus/relais_heizung/get/" + str(i+1), "on")
else:
client.publish("modbus/relais_heizung/get/" + str(i+1), "off")
def on_connect(client, userdata, flags, rc):
print("Connected with result code "+str(rc))
client.subscribe("modbus/relais_heizung/set/#")
def on_message(client, userdata, msg):
splitted_topic = msg.topic.split("/")
relay = splitted_topic[3]
print("Relay " + relay + " " + msg.payload.decode())
ready = False
while not(ready):
if relais_freigabe:
set_relais(relay, msg.payload.decode())
time.sleep(0.1)
get_relais()
ready = True
else:
print("Warte 1 sek")
time.sleep(1)
client = mqtt.Client()
client.connect("localhost",1883,60)
client.on_connect = on_connect
client.on_message = on_message
get_relais()
client.loop_start()
while True:
try:
time.sleep(0.1)
time1 = time.perf_counter()
# ------------------ Modbus Heizung ------------------
modbus_instrument = "/dev/serial/by-id/usb-1a86_USB_Serial-if00-port0"
name = "heizung"
# ------------------
# try:
modbuszaehler = minimalmodbus.Instrument('/dev/serial/by-id/usb-1a86_USB_Serial-if00-port0', 1, debug = True)
modbuszaehler.serial.timeout = 1.0
print(modbuszaehler)
input_register = {
"Spannung_L1": {
"port": 0, "digits": 2, "Unit": "V", "use": True},
"Spannung_L2": {
"port": 2, "digits": 2, "Unit": "V", "use": True},
"Spannung_L3": {
"port": 4, "digits": 2, "Unit": "V", "use": True},
"Strom_L1": {
"port": 6, "digits": 2, "Unit": "A", "use": True},
"Strom_L2": {
"port": 8, "digits": 2, "Unit": "A", "use": True},
"Strom_L3": {
"port": 10, "digits": 2, "Unit": "A", "use": True},
"Wirkleistung_L1": {
"port": 12, "digits": 2, "Unit": "W", "use": True},
"Wirkleistung_L2": {
"port": 14, "digits": 2, "Unit": "W", "use": True},
"Wirkleistung_L3": {
"port": 16, "digits": 2, "Unit": "W", "use": True},
"Scheinleistung_L1": {
"port": 18, "digits": 2, "Unit": "VA", "use": True},
"Scheinleistung_L2": {
"port": 20, "digits": 2, "Unit": "VA", "use": True},
"Scheinleistung_L3": {
"port": 22, "digits": 2, "Unit": "VA", "use": True},
"Blindleistung_L1": {
"port": 24, "digits": 2, "Unit": "VAr", "use": True},
"Blindleistung_L2": {
"port": 26, "digits": 2, "Unit": "VAr", "use": True},
"Blindleistung_L3": {
"port": 28, "digits": 2, "Unit": "VAr", "use": True},
"Leistungsfaktor_L1": {
"port": 30, "digits": 2, "Unit": "", "use": True},
"Leistungsfaktor_L2": {
"port": 32, "digits": 2, "Unit": "", "use": True},
"Leistungsfaktor_L3": {
"port": 34, "digits": 2, "Unit": "", "use": True},
"Phasenwinkel_L1": {
"port": 36, "digits": 2, "Unit": "Grad", "use": True},
"Phasenwinkel_L2": {
"port": 38, "digits": 2, "Unit": "Grad", "use": True},
"Phasenwinkel_L3": {
"port": 40, "digits": 2, "Unit": "Grad", "use": True},
"Durchschnittliche_Spannung_zu_N": {
"port": 42, "digits": 2, "Unit": "V", "use": True},
"Durchschnittlicher_Strom_zu_N": {
"port": 46, "digits": 2, "Unit": "A", "use": True},
"aktueller_Gesamtstrom": {
"port": 48, "digits": 2, "Unit": "A", "use": True},
"aktuelle_Gesamtwirkleistung": {
"port": 52, "digits": 2, "Unit": "W", "use": True},
"aktuelle_Gesamtscheinleistung": {
"port": 56, "digits": 2, "Unit": "VA", "use": True},
"aktuelle_Gesamtblindleistung": {
"port": 60, "digits": 2, "Unit": "VAr", "use": True},
"aktueller_Gesamtleistungsfaktor": {
"port": 62, "digits": 2, "Unit": "", "use": True},
"aktueller_Gesamtphasenwinkel": {
"port": 66, "digits": 2, "Unit": "A", "use": True},
"Frequenz": {
"port": 70, "digits": 2, "Unit": "Hz", "use": True},
"Import_Wh_seit_reset": {
"port": 72, "digits": 2, "Unit": "kWh", "use": True},
"Export_Wh_seit_reset": {
"port": 74, "digits": 2, "Unit": "kWH", "use": True},
"Import_VArh_seit_reset": {
"port": 76, "digits": 2, "Unit": "kVArh", "use": True},
"Export_VArh_seit_reset": {
"port": 78, "digits": 2, "Unit": "kVArh", "use": True},
"VAh_seit_reset": {
"port": 80, "digits": 2, "Unit": "kVAh", "use": True},
"Ah_seit_reset": {
"port": 82, "digits": 2, "Unit": "Ah", "use": True},
"Gesamtwirkleistung": {
"port": 84, "digits": 2, "Unit": "W", "use": True},
"Max_Gesamtwirkleistung": {
"port": 86, "digits": 2, "Unit": "W", "use": True},
"Gesamtscheinleistung": {
"port": 100, "digits": 2, "Unit": "VA", "use": True},
"Max_Gesamtscheinleistung": {
"port": 102, "digits": 2, "Unit": "VA", "use": True},
"Gesamtstrom_Neutralleiter": {
"port": 104, "digits": 2, "Unit": "A", "use": True},
"Max_Strom_Neutralleiter": {
"port": 106, "digits": 2, "Unit": "A", "use": True},
"Spannung_L1_L2": {
"port": 200, "digits": 2, "Unit": "V", "use": True},
"Spannung_L2_L3": {
"port": 202, "digits": 2, "Unit": "V", "use": True},
"Spannung_L3_L1": {
"port": 204, "digits": 2, "Unit": "V", "use": True},
"Durchschnittsspannung_L_L": {
"port": 206, "digits": 2, "Unit": "V", "use": True},
"Strom_Neutralleiter": {
"port": 224, "digits": 2, "Unit": "A", "use": True},
"THD_Spannung_L1": {
"port": 234, "digits": 2, "Unit": "%", "use": True},
"THD_Spannung_L2": {
"port": 236, "digits": 2, "Unit": "%", "use": True},
"THD_Spannung_L3": {
"port": 238, "digits": 2, "Unit": "%", "use": True},
"THD_Strom_L1": {
"port": 240, "digits": 2, "Unit": "%", "use": True},
"THD_Strom_L2": {
"port": 242, "digits": 2, "Unit": "%", "use": True},
"THD_Strom_L3": {
"port": 244, "digits": 2, "Unit": "%", "use": True},
"THD_Durchschnittliche_Spannung_zu_N": {
"port": 248, "digits": 2, "Unit": "%", "use": True},
"THD_Durchschnittlicher_Strom_zu_N": {
"port": 250, "digits": 2, "Unit": "%", "use": True},
"Strom_L1_demand": {
"port": 258, "digits": 2, "Unit": "A", "use": True},
"Strom_L2_demand": {
"port": 260, "digits": 2, "Unit": "A", "use": True},
"Strom_L3_demand": {
"port": 262, "digits": 2, "Unit": "A", "use": True},
"Max_Strom_L1_demand": {
"port": 264, "digits": 2, "Unit": "A", "use": True},
"Max_Strom_L2_demand": {
"port": 266, "digits": 2, "Unit": "A", "use": True},
"Max_Strom_L3_demand": {
"port": 268, "digits": 2, "Unit": "A", "use": True},
"THD_Spannung_L1_L2": {
"port": 334, "digits": 2, "Unit": "%", "use": True},
"THD_Spannung_L2_L3": {
"port": 336, "digits": 2, "Unit": "%", "use": True},
"THD_Spannung_L3_L1": {
"port": 338, "digits": 2, "Unit": "%", "use": True},
"THD_Durchschnittliche_Spannung_zu_L_L": {
"port": 340, "digits": 2, "Unit": "%", "use": True},
"Total_kwh": {
"port": 342, "digits": 2, "Unit": "kwh", "use": True},
"Total_kvarh": {
"port": 344, "digits": 2, "Unit": "kvarh", "use": True},
"Import_L1_kwh": {
"port": 346, "digits": 2, "Unit": "kwh", "use": True},
"Import_L2_kwh": {
"port": 348, "digits": 2, "Unit": "kwh", "use": True},
"Import_L3_kwh": {
"port": 350, "digits": 2, "Unit": "kwh", "use": True},
"Export_L1_kwh": {
"port": 352, "digits": 2, "Unit": "kwh", "use": True},
"Export_L2_kwh": {
"port": 354, "digits": 2, "Unit": "kwh", "use": True},
"Export_L3_kwh": {
"port": 356, "digits": 2, "Unit": "kwh", "use": True},
"Gesamtstrom_L1_kwh": {
"port": 358, "digits": 2, "Unit": "kwh", "use": True},
"Gesamtstrom_L2_kwh": {
"port": 360, "digits": 2, "Unit": "kwh", "use": True},
"Gesamtstrom_L3_kwh": {
"port": 362, "digits": 2, "Unit": "kwh", "use": True},
"Import_L1_kvarh": {
"port": 364, "digits": 2, "Unit": "kvarh", "use": True},
"Import_L2_kvarh": {
"port": 366, "digits": 2, "Unit": "kvarh", "use": True},
"Import_L3_kvarh": {
"port": 368, "digits": 2, "Unit": "kvarh", "use": True},
"Export_L1_kvarh": {
"port": 370, "digits": 2, "Unit": "kvarh", "use": True},
"Export_L2_kvarh": {
"port": 372, "digits": 2, "Unit": "kvarh", "use": True},
"Export_L3_kvarh": {
"port": 374, "digits": 2, "Unit": "kvarh", "use": True},
"Total_L1_kvarh": {
"port": 376, "digits": 2, "Unit": "kvarh", "use": True},
"Total_L2_kvarh": {
"port": 378, "digits": 2, "Unit": "kvarh", "use": True},
"Total_L3_kvarh": {
"port": 380, "digits": 2, "Unit": "kvarh", "use": True},
}
heizung_json_body = [
{
"measurement": name,
"fields": {}
},
]
relais_freigabe = False
for key in input_register:
if input_register[key]["use"] == True:
heizung_json_body[0]["fields"][key] = round(modbuszaehler.read_float(functioncode=4, registeraddress=input_register[key]["port"], number_of_registers=input_register[key]["digits"]), 2)
relais_freigabe = True
# ------------------ Tasmota Haus ------------------
tasmota_url = "http://tasmota-1ae72e-1838.fritz.box"
name = "tasmota_haus"
# ------------------
try:
r = requests.get(tasmota_url + "/cm?cmnd=status%2010")
json = r.json()
tasmota_values = {}
tasmota_haus_json_body = [
{
"measurement": name,
"fields": {}
},
]
for key in json["StatusSNS"]["MT175"]:
try:
tasmota_values[key] = float(json["StatusSNS"]["MT175"][key])
except:
tasmota_values[key] = str(json["StatusSNS"]["MT175"][key])
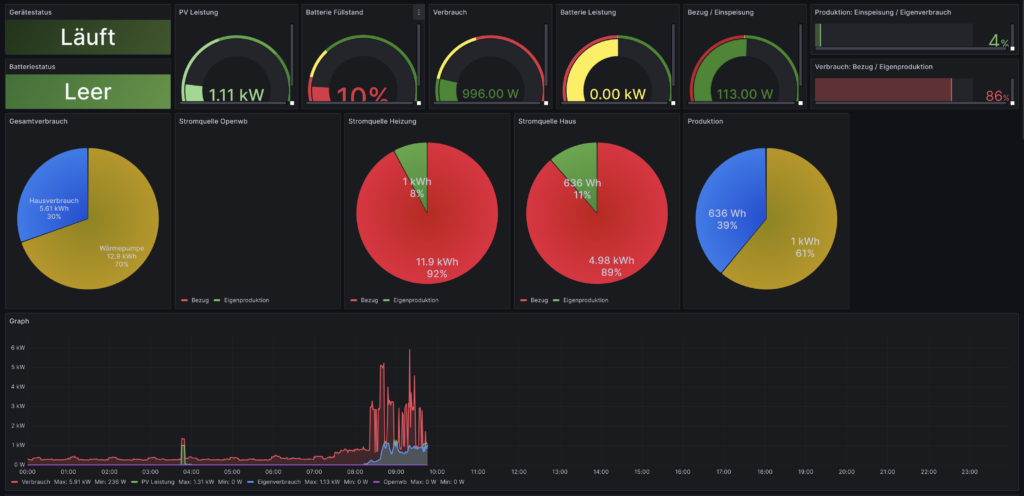
tasmota_haus_json_body[0]['fields']['Leistung'] = tasmota_values['Power_curr']
tasmota_haus_json_body[0]['fields']['Import_kWh'] = tasmota_values['Total']
tasmota_haus_json_body[0]['fields']['Export_kWh'] = tasmota_values['Total_out']
#print(tasmota_haus_json_body)
except:
print("Fehler beim Lesen von Tasmota Haus")
# ------------------ Tasmota Heizung ------------------
tasmota_url = "http://tasmota-1ae72e-1838.fritz.box"
name = "tasmota_heizung"
# ------------------
try:
r = requests.get(tasmota_url + "/cm?cmnd=status%2010")
json = r.json()
tasmota_values = {}
tasmota_heizung_json_body = [
{
"measurement": name,
"fields": {}
},
]
for key in json["StatusSNS"]["METER1"]:
try:
tasmota_values[key] = float(json["StatusSNS"]["METER1"][key])
except:
tasmota_values[key] = str(json["StatusSNS"]["METER1"][key])
tasmota_heizung_json_body[0]['fields']['Leistung'] = tasmota_values['Power_curr']
tasmota_heizung_json_body[0]['fields']['Import_kWh'] = tasmota_values['Total']
tasmota_heizung_json_body[0]['fields']['Export_kWh'] = tasmota_values['Total_out']
#print(tasmota_heizung_json_body)
except:
print("Fehler beim Lesen von Tasmota Haus")
# ------------------ Heizungsleistung berechnen ------------------
try:
heizung_json_body[0]['fields']['Leistung'] = tasmota_heizung_json_body[0]['fields']['Leistung']-tasmota_haus_json_body[0]['fields']['Leistung'] + heizung_json_body[0]['fields']['aktuelle_Gesamtwirkleistung']
if(tasmota_heizung_json_body[0]['fields']['Leistung']>=0 and tasmota_haus_json_body[0]['fields']['Leistung']>=0): # Voll Netzbetrieb
heizung_json_body[0]['fields']['Leistung_Netz'] = heizung_json_body[0]['fields']['Leistung']
heizung_json_body[0]['fields']['Leistung_PV'] = 0.0
elif(tasmota_heizung_json_body[0]['fields']['Leistung']<=0 and tasmota_haus_json_body[0]['fields']['Leistung']<=0): # PV Betrieb
heizung_json_body[0]['fields']['Leistung_Netz'] = 0.0
heizung_json_body[0]['fields']['Leistung_PV'] = heizung_json_body[0]['fields']['Leistung']
else: #Mischung
heizung_json_body[0]['fields']['Leistung_Netz'] = tasmota_heizung_json_body[0]['fields']['Leistung']
heizung_json_body[0]['fields']['Leistung_PV'] = tasmota_haus_json_body[0]['fields']['Leistung']*-1
# Modbus Leistung dazurechnen
heizung_json_body[0]['fields']['Leistung_Modbus'] = heizung_json_body[0]['fields']['aktuelle_Gesamtwirkleistung']
except:
print("Fehler beim Berechnen von Heizungsleistung")
# ------------------ Zählerstand Heizung berechnen ------------------
heizung_json_body[0]['fields']['Zaehlerstand_Einspeisung'] = tasmota_haus_json_body[0]['fields']['Export_kWh'] - tasmota_heizung_json_body[0]['fields']['Export_kWh']
heizung_json_body[0]['fields']['Zaehlerstand_Bezug'] = tasmota_heizung_json_body[0]['fields']['Import_kWh'] - tasmota_haus_json_body[0]['fields']['Import_kWh']
heizung_json_body[0]['fields']['Zaehlerstand_PV'] = heizung_json_body[0]["fields"]['Total_kwh']
print(heizung_json_body)
influxclient.write_points(heizung_json_body)
# except:
# print("Fehler beim Lesen von Modbuszähler Heizung")
time2 = time.perf_counter()
timedifference = time2-time1
if timedifference < 60:
time.sleep(60-timedifference)
except:
print("Fehler beim Auslesen vom Modbuszähler")
time.sleep(60)